BIG DATA & HADOOP
- INTRODUCCIÓN BIG DATA
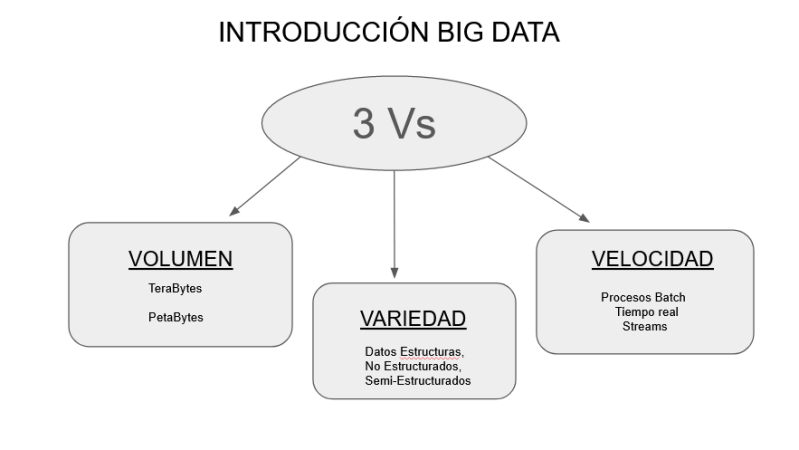
BIG DATA, la podemos llamar como conjuntos de datos demasiado grandes y complejos para que los sistemas tradicionales de almacenamiento lo pueden almacenar y procesar. Por lo que nace la necesidad de una nueva tecnología que trate de dar solución a las 3 Vs (Volumen, Velocidad, Variedad)
Todos estos datos se generan de forma rapida a través de las redes sociales, movíles, datos cientificos, sociales y financieros, etc... es decir todo lo que esta conectado a nuestro mundo en internet y en la nubes de datos.
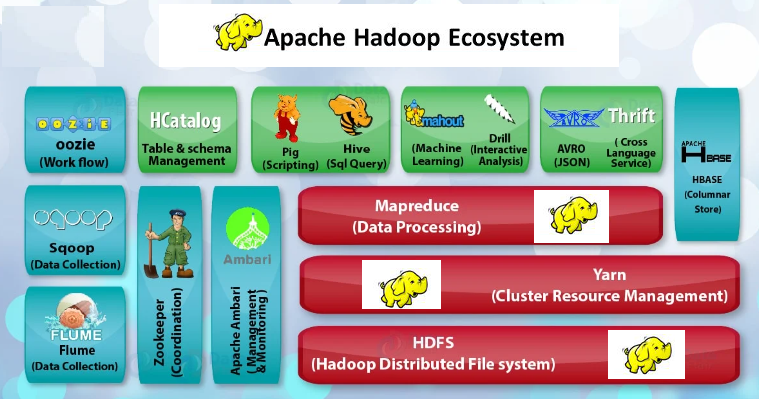
TRABAJOS REALIZADOS - INSTALACIÓN HADOOP 3.2.3 EN LINUX UBUNTU SERVER
VIDEO - 3.- Instalamos java y comprobar que versión dejamos operativa
VIDEO - 4.-Descargar y dejamos instlado hadoop 3.2.3
VIDEO - 5.-Configuraciones variable entorno de hadoop
VIDEO - 6.- Editamos y configuramos el fichero hadoop_env.sh
VIDEO - 7.-Descargamos y configuramos javax
VIDEO - 8.-Configuramos el archivo core-site.xml
VIDEO - 9.-Configuramos el archivo hdfs-site.xml
VIDEO - 10.-Configuramos el archivo mapred-site.xml
VIDEO - 11.-Configuramos el archivo yarn-site.xml
VIDEO - 12.-Damos formato HDFS del NameNode
VIDEO - 13.-Arrancamos el NameNode, DataNode y YARN
VIDEO - 14.-Revisamos si todas las conexiones funciona
Crea tu propia página web con Webador